【はじめに】ノーム・チョムスキーとプログラミング言語

ノーム・チョムスキーは、現代のプログラミング言語の設計やコンパイラの仕組みにおいて、極めて重要な(というより不可欠な)役割を果たしています。
彼は言語学者ですが、1950年代に提唱した「チョムスキー階層」という理論が、コンピュータサイエンスの基礎理論の一つとなりました。
チョムスキーは、言語の文法をその複雑さに応じて4つの階層に分類しました。これがそのまま、プログラミング言語の「解析のしやすさ」と「計算能力」の基準になっています。
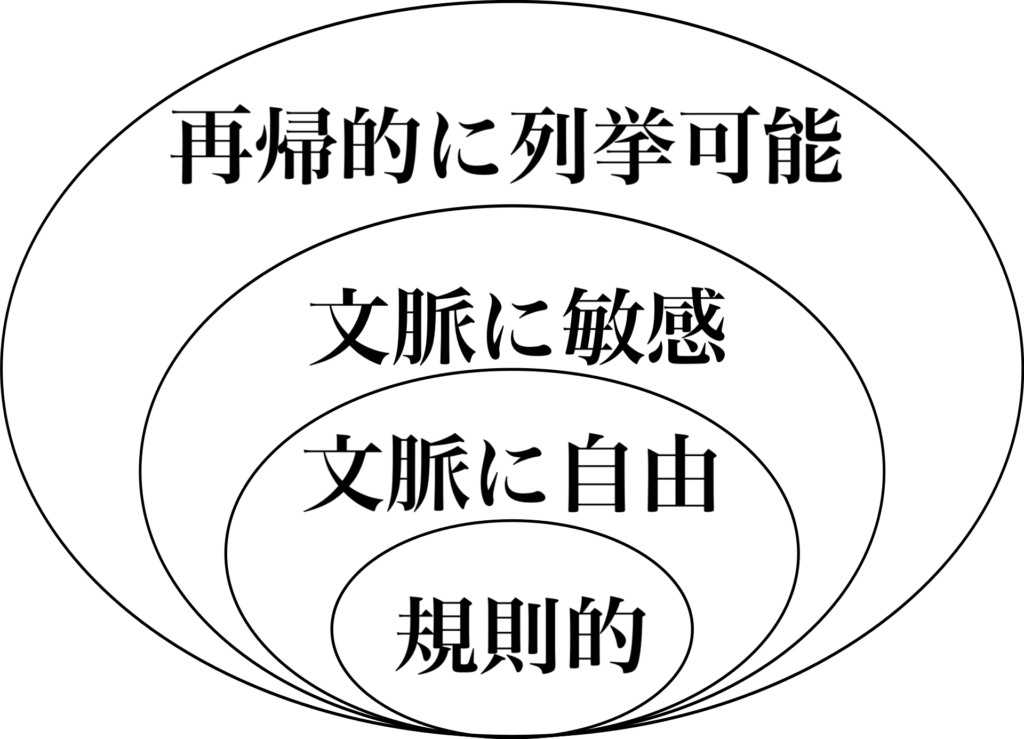
①正規言語 (Type-3)
- 正規表現。字句解析。
- もっとも単純な構造。文字列の検索や、ソースコードを「単語」単位に切り分ける際に使われます。
- 正規表現でトークン(単語)に分ける。
②文脈自由言語 (Type-2):主役👑
- ほとんどのプログラミング言語の構文。構文解析。
- 括弧の対応や、入れ子構造を表現できます。コンパイラが「このコードの文法は正しいか?」を判定する構文解析の心臓部です。
- 文脈自由文法で木構造(抽象構文木/AST)を作る。
③文脈依存言語 (Type-1)
- 意味解析(パース)。変数の二重定義チェックなど。
- 周囲の状況によって意味が変わるルール。複雑すぎて、プログラミング言語の構文そのものにはあまり使われませんが、意味解析の一部に関係します。
④無制限文法 / 帰納的可算集合 (Type-0)
- チューリングマシン。現代のコンピュータそのもの。
- どんな計算でも表現できる、最強の階層。これはコンピュータ理論のチューリングマシンと同等です。
プログラミング言語との深い関係性とは?
- コンパイラの設計→プログラムを機械語に翻訳する際、「字句解析」→「構文解析」を行う。この構文解析のアルゴリズムは、チョムスキーが定義した「文脈自由文法」に基づいています。
- 言語の定義→プログラミング言語仕様は、チョムスキーの理論を発展させた「バッカス・ナウア記法」で記述されるのが一般的です。
- 計算機科学→「オートマトン(計算モデル)と形式言語」はほぼチョムスキーの話と言っても過言ではない。
ノーム・チョムスキーの影響力
彼は「言語学の父」であると同時に、実質的には「コンピュータサイエンスの重要人物」でもあります。
ノーム・チョムスキーがいなければ、現代の効率的なコンパイラや、厳密な文法を持つプログラミング言語(Java, Rust, Pythonなど)は存在しなかったか、あるいは全く別の非常に非効率な形になっていたでしょう。
プログラミング言語の4つの思想
- 手続き型(PP)
- 低レイヤ、計算
- OS開発、組み込みシステム、高速な数値計算
- C言語, Fortran, BASIC, Pascal
- オブジェクト指向(OOP)
- 大規模アプリ
- 大規模なシステム開発、GUIアプリ、ゲーム開発、Webサーバー
- Java, C++, Python, Ruby, C#
- 関数型(FP)
- 並列処理、安全性、副作用を排除
- 並列処理、バグが許されない金融システム、UIの状態管理
- Haskell, Lisp, Elixir, Elm
- 命令型(IP)
- 状態(変数)の変更、制御フロー、コンピュータの仕組みに忠実
- メモリやCPUの性能を限界まで引き出す処理
- C言語, Java, Python, Ruby, Go, C++, PHP
マルチパラダイム言語
現代の主要なプログラミング言語は、ほとんどがマルチパラダイム言語です。一つの思想に縛られず、それぞれの良いところ(OOPの構造化、関数型の安全性、手続き型の効率など)を組み合わせています。

Rust(高速で厳格で安全)
「手続き型 × 関数型 」
- 【手続き型】低レイヤを制御する強力なループやポインタ操作が可能
- 【関数型】強力な関数型由来の機能を備えている。
- 代数的データ型(Enum)、パターンマッチング、イテレータ(map, filterなど)
- 「所有権」という独自の思想
React(宣言的なUI)
「宣言型 × 関数型 」
- 【宣言型】状態に基づいた「あるべき姿」を記述し、DOM操作を抽象化
- 【関数型】Hooksの活用で、UIを純粋な関数の組み合わせとして構築
- 仮想DOMにより、開発者が複雑な手順を書かなくても効率的な画面更新を実現
TypeScript / JavaScript(多機能であり柔軟)
「オブジェクト指向 × 関数型」
- 【オブジェクト指向】データ指向でクラスを使った大規模な設計が可能
- 【関数型】関数を第一級オブジェクトとして扱い、高階関数を多用します。
- 「プロトタイプ x OOP」
- 特殊な形態であるプロトタイプベースの性質も根底に持っています
Python(読みやすくシンプル)
「オブジェクト指向 × 手続き型 × 関数型」
- 【オブジェクト指向】すべてのデータがオブジェクトとして設計されている
- 【手続き型】スクリプトとして上から順に書くスタイルが基本
- 【関数型】ラムダ(名無し関数)やリスト内包表記など、関数型的なデータ処理が得意
Swift / Kotlin(スマホアプリ用言語)
「オブジェクト指向 × 関数型」
- 【オブジェクト指向】クラスやインターフェースによる堅牢な設計
- 【関数型】Optional型による安全な値の扱いや、クロージャを用いた簡潔な記述
- 「宣言型UI」SwiftUIやJetpack Compose(Kotlin)といった、宣言的UIフレームワークとの親和性が非常に高い
それぞれの思想のトレードオフ(メリット・デメリット)
それぞれの思想には、得意な領域がある一方で、”絶対”であり”必ず”トレードオフ(何かを得るために何かを捨てること)が存在します。
命令型 (IP)
学習は容易で実行速度は早いが、大規模開発では複雑さがネックとなります。

- メリット
- 直感的:人間の思考や指示に近く、初心者でも始めやすい。
- 効率がとても良い:CPUやメモリの動作に忠実なため、無駄がなく、実行速度を極限まで高められる。(特にC/C++/Rust/Goなど)
- デメリット
- 副作用(予期せぬバグ)の制御が困難:変数をどこでも書き換えられる(カプセル化が難しく、隠蔽性が低い)ため、規模が大きくなりコードが複雑化した場合、バグりやすく、バグの特定も困難。
- 並列処理に弱い:複数の場所から同時に同じデータを書き換えると、データが壊れる危険。データが壊れる「競合」が発生しやすい。
- よく用途される場面
- とても小さいスクリプト(数十行程度)
- 学習用
- プロトタイピング(素早く動くものを作る場合)
- 競技プログラミング
- 向いている状況
- 10〜100行程度のワンショットスクリプト
- AtCoder・競プロ
- シェルスクリプト置き換え(PythonやGoで書くことが増えている)
- 向いていない状況
- 100行超えるとすぐにスパゲッティ化する
- チーム開発・長期保守が必要なプロジェクトには向いてない
手続き型 (PP)
学習コストが低くシンプルで高速ですが、再利用性・保守性に限界があります。

- メリット
- シンプル:小~中規模の開発では学習コストが低い、「処理を手順として関数に分けるだけ」で済む。
- 移植性:ハードウェアを直接制御しやすく、C言語やGoがOS・ミドルウェア・インフラツールの基盤としては、非常に強い。
- デメリット
- スパゲッティコード:規模が大きくなると、関数同士が複雑に絡み合い、修正の影響範囲が分からなくなる。
- データの保護・カプセル化が弱い:グローバル変数やポインタ経由でどこからでもデータを触れてしまうため、どこからでもデータが触れられる。
- よく用途される場面
- 中〜大規模なC言語プロジェクト
- 組み込み系・IoT・ファームウェア
- インフラツール・CLIツール・サーバーサイド基盤(Go言語が特に強い)
- 昔ながらの業務システム(レガシーなソフトウェア:COBOL, Fortran, C)
- 向いてる状況
- 関数単位で再利用したいが、クラス・オブジェクト設計までしたくないとき
- C / Go / Rust(手続きスタイル寄り)で書く中規模ツール
- 向いていない状況
- ドメインが複雑でデータと振る舞いが密接な場合(→オブジェクト指向や関数型が有利となる)
(補足)多くの人が「命令型 = 手続き型」と扱う
「命令型(IP)」と「手続き型(PP)」を別々に書いているが、実務ではほぼ重なる。
(補足)手続き型+構造化
業務で使われる現代のほぼ全ての命令型コード
- 向いている状況
- ほとんどの実務コード(Python, Go, Rust, JavaScript, TypeScriptなど)
- オブジェクト指向にしなくてもいいけど、スパゲッティにはしたくない中規模プロジェクトの場合
オブジェクト指向 (OOP)
学習コストは中程度で、大規模で複雑なドメインを扱うときに一番の強みが出る。データ指向(DOP)の考え方も補完的に取り入れるとさらに強力。

- メリット
- 現実世界のモデル化が直感的:エンティティとその振る舞いをクラスで表現しやすい → ビジネスドメインが複雑なシステムで理解しやすい。
- カプセル化・情報隠蔽が強い:データと操作を1つにまとめ、外部からの直接アクセスを制限 → 副作用を局所化しやすく、変更時の影響範囲をコントロールしやすい。
- 継承・ポリモーフィズムで再利用・拡張性:共通機能を基底クラスにまとめ、サブクラスで特殊化 → 大規模チームでの分業・保守がしやすい。
- エコシステムが圧倒的に豊富:Java, C#, Kotlin, TypeScript, Python, Swiftなど、ほぼ全てのメジャー言語で本格サポート。
- デメリット(アンチ多すぎるだろ!!💀💀💀)
- 過剰設計・神クラス・アノミックドメイン:継承乱用で深い階層ができたり、無意味な抽象化でコードが肥大化。
- 可変状態でバグりやすい:オブジェクトの状態がどこからでも変わる → 並行処理でrace condition(競争バグ/タイミング依存バグ)が頻発しやすい。
- ボイラープレート:getter/setter、コンストラクタ、toStringなど儀式的なコードが増える。
- 学習曲線が急:SOLID原則・デザインパターン・クリーンアーキテクチャなどをちゃんと理解しないと逆効果。
- よく使われる場面(今でも一番よく使われています!!😊✌️👑)
- エンタープライズ業務システム(銀行、ERP、CRM、ECバックエンド)
- 大規模Webアプリケーション(Spring Boot, .NET, Laravel, Railsなど)
- モバイルアプリ(Android/Kotlin, iOS/Swift)
- ゲーム開発(Unity/C#の伝統的OOP部分、Unreal/C++)
- ドメイン駆動設計(DDD)が必要な中〜超大規模プロジェクト
- データ指向ハイブリッド:Java/Kotlinのrecord + pattern matchingでドメインロジックをシンプルに(不変データが中心)
- 向いている状況
- ビジネスルールが複雑で、エンティティ間の関係性・ライフサイクルをしっかりモデル化したい
- チーム規模10人以上・長期保守(5〜10年以上)が見込まれる
- 状態を持つUIコンポーネントやドメインオブジェクトが多い
- データ指向をミックス:immutable(不変)データ + 振る舞い分離でOOPの弱点をカバーしたい場合(Java 21+, Kotlinなど)
- 向いていない状況
- 超高並列・データフローが中心のシステム(FPや純粋データ指向有利)
- スクリプト・データ変換・機械学習パイプライン(命令型/関数型で十分)
- パフォーマンスが極限まで必要な部分(データ指向設計/ECSが強い)
(補足)純粋データ指向(DOD/DOP)とは
データを中心に設計し、コード(振る舞い)とデータを完全に分離する。
- パフォーマンス重視のデータ指向(DOD)とアプリケーション設計重視のデータ指向がある(DOP)
- (例)DOPの原則:
- データとコードを分離
- データは汎用構造(map/recordなど)
- immutable(不変)にする
- スキーマと表現を分離
- パフォーマンス(速度/効率)では、純粋データ指向が明らかに強い場面が多いが、ビジネスロジックが複雑なシステムやコードの読みやすさ・メンテナンス性ではオブジェクト指向が強い。
関数型 (FP)
学習コストは最初高いが、一度慣れるとコードが劇的にシンプル・安全・並行処理に強い。

- メリット(安全性がたくさんの人を魅了する🫣)
- 参照透過性・純粋関数:同じ入力なら必ず同じ出力でテストが極端に書きやすくバグが激減。
- immutable(不変)データ:副作用がほぼなくなり、並列・並行処理が安全で簡単(競争バグ/タイミング依存バグがほぼ起きない)。
- 高階関数・合成・パイプライン: コードが宣言的で短く、何をするかが明確で、可読性・メンテナンス性が爆上がり。
- エラー処理が型安全:null/nil地獄や例外ハンドリングが減る。
- デメリット(学習コストは高そうだ💀💀💀)
- 思考の転換が非常に難しい:命令型脳だとHow(どうやる?)を抑えるのが苦痛。
- パフォーマンスオーバーヘッド頻発:immutable(不変)だとコピー多発でGC圧力・メモリ使用量が増える(しかし、最適化でかなり改善する)
- エコシステムがまだ成熟していない:純粋FP言語(Haskell, OCaml)はニッチでマジのオタク向け。主流言語では「FP風」に寄せる形が多い。
- デバッグが独特:スタックトレースが深くなりがち、lazy評価(式を書いても、すぐ計算せず待つ)で挙動が予想外になることも。
- よく使われる場面
- データ処理・ETLパイプライン(Spark/Scala, Pandas/Polars/Python FP風, Elixir)
- バックエンドAPI(特に並行性が高いもの:Goのgoroutine + FP風, Rust, Elixir/Phoenix)
- フロントエンド(React + hooks + immutable state, Elm, ReScript, PureScript)
- 金融・ブロックチェーン・暗号(正確性が命:Haskell, OCaml, F#, Scala)
- AI/機械学習のコアロジック(JAX, PyTorchの関数型API部分)
- サーバーレス・イベント駆動(AWS Lambdaなど短命プロセス)
- ネイティブ言語(宣言的UIや厳格性を持つコンパイルなど)
- 向いている状況
- 並行・並列処理が多く、状態変更によるバグが致命的なシステム
- データ変換・ストリーム処理が中心
- テスト容易性・正確性が最優先(金融、医療、航空宇宙など)
- コード量を抑えつつ高い信頼性を求める
- 向いていない状況
- 状態が頻繁に変わるUI/ゲーム(→ OOPや命令型が直感的)
- レガシーシステムの保守・大規模チームで全員がFP未経験
- 極端なパフォーマンス(メモリ/CPU)が求められる低レイヤー部分
NULLの誕生が10億ドル(約1,500億円前後)の損害を引き起こした

null参照の概念を発明した、Tony Hoare本人が「私の失敗で10億ドル損させた」って本人が言っている。関数型やnull安全を備えた言語は、NULL参照のバグを起こしにくくする。
最近のトレンド
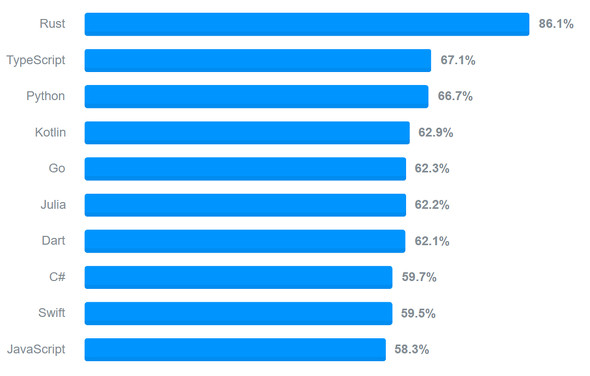
Rust:「最愛言語」としてStack Overflow調査で9年連続トップ
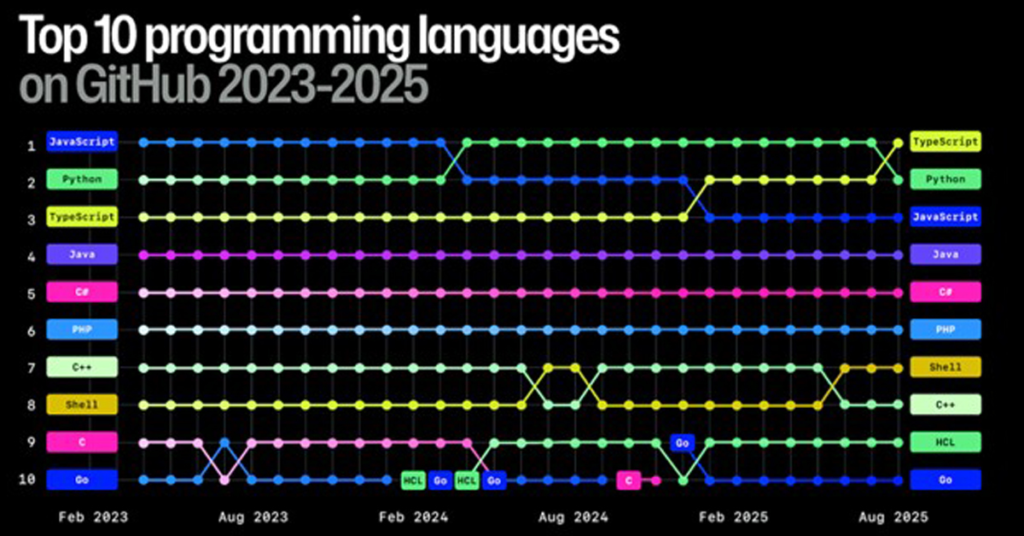
TypeScript:GitHubでPythonを抜いてトップ(2025 Octoverse)
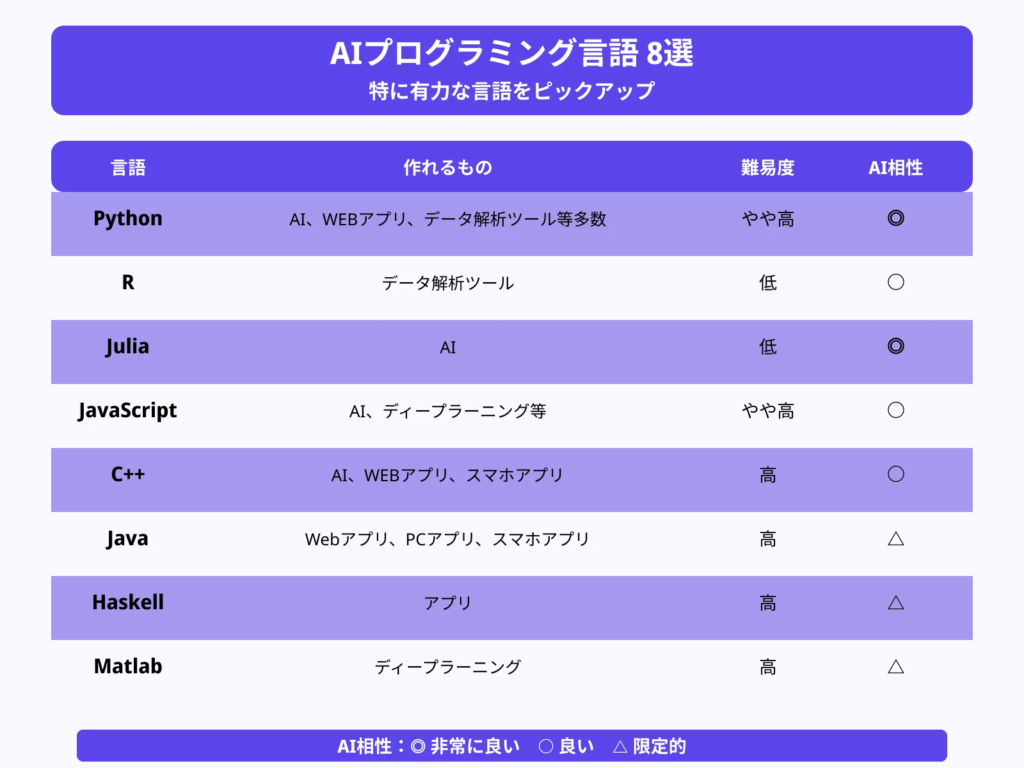
Python:AI/データで不動の王者。
まとめ
コンパイラや文法の基礎は「チョムスキー階層」のおかげで成り立っている。
- 安全性・並列重視: 関数型(FP)やnull安全(Rust/Kotlin/Swift)の強み
- 大規模ドメイン・チーム開発:オブジェクト指向(OOP)が今でも最強💪🤩
- パフォーマンス極限:データ指向(DOD)やRustの手続き + FPハイブリッド
現代の主流言語はすべてマルチパラダイム。
純粋言語は少なく、ハイブリッドにRust(手続き + FP + 所有権)、React(宣言型 + FP)、Python/TypeScript(OOP + FP + PP)のように、良いところ取りが現在の主流です。チョムスキーの理論がなければ、今日のコンパイラや言語はここまで効率的じゃなかったはずです!!!!
彼に感謝しつつ、それぞれの特性を理解して、楽しくコードを書いていきましょう!
ABOUT ME
2002年生まれの学生です。
趣味は小説を読むことです。たまに技術書も読みます。







