
ハムスターの洞窟を買ってみた!!
palm
Palm Blog

現在、App Storeに登録するのを目標にとあるアプリを実装しています。
REST、Cleanの本を読み、DDD(ドメイン駆動設計)も実装に挑戦してみたいと思い、認証・認可まで実装が終わりました。
それぞれの特性を尊重し、厳格に守り、綺麗なアーキテクチャを保ちたい。
“RESTと呼ばれているもの”、”RESTっぽい”で終わらせたくない。
チェックリストを用意し、そんな思いで実装してみました。
「アプリケーション状態がハイパーテキストによって駆動されていない API は REST ではない」

REST API は、分散型ハイパーメディア・システムの接続に使用される方式である、Representational State Transfer (REST) アーキテクチャー方式の設計原則に準拠したAPIです。REST APIは、RESTful APIまたはRESTful Web APIと呼ばれることもあります。
RESTは、開発者に比較的高いレベルの柔軟性、一貫性、拡張性、効率性を実現します。REST APIは、Web APIを構築するための軽量な方法です。
ハイパーメディアシステム:分散システム. ハイパーメディア. 画像、音声、映像などさまざまなメディアをハイパーリンクで結びつけた構成システムのこと。
今回の認証/認可の実装で気をつけた定義を紹介します。
統一されたエンドポイント設計
POST /v1/auth/signup:ユーザーの新規登録リクエストPOST /v1/auth/login:認証トークン発行のためのログインリクエストGET /v1/me :現在の認証済みユーザー情報を取得HTTPメソッドは、リソースの操作内容に基づき正しく選定しました。(POSTをデータ生成処理に使用、GETをデータ取得に使用など)
// サインアップ用ユースケースの生成
signupUC := authuc.SignupUsecase{Users: d.Users, Hasher: d.Hasher, Tokens: d.Tokens, TTL: 15 * time.Minute}
// ログイン用ユースケースの生成
loginUC := authuc.LoginUsecase{Users: d.Users, Hasher: d.Hasher, Tokens: d.Tokens, TTL: 15 * time.Minute}
// 自分の情報取得用ユースケースの生成
getMeUC := meuc.GetMeUsecase{Users: d.Users}
// ハンドラーにユースケースを渡して生成
ah := authhttp.AuthHandler{Signup: signupUC, Login: loginUC}
// GET /v1/me に対応するハンドラー
mh := mehttp.MeHandler{GetMe: getMeUC}一貫性のあるレスポンス設計
クライアントがレスポンスコード(404、201)を見れば、その状態を理解しやすいようになります。
// エラーをHTTPレスポンスに変換
if errors.Is(err, auth.ErrInvalidCredentials) {
http.Error(w, "unauthorized", http.StatusUnauthorized) // ステータスコード 401
return
}
if errors.Is(err, auth.ErrEmailAlreadyExists) {
http.Error(w, "email already exists", http.StatusConflict) // ステータスコード 409
return
}役割の分離
サーバーとクライアントの役割が明確に分かれるようになります。
拡張性の確保
// トークンが有効かを先に確認
let (meData, meResponse) = try await apiClient.request(
"GET",
path: "v1/me",
requiresAuth: true
)
let meBody = String(data: meData, encoding: .utf8) ?? "<non-utf8 response>"
try apiClient.validate(meResponse, data: meData)
print("[Debug][me] status=\(meResponse.statusCode) body=\(meBody)")認証の簡易性とシンプルさ
スケーラブルで高速なAPI認証に最適
// JWTトークンの発行例
tok, exp, err := uc.Tokens.IssueAccessToken(rec.ID, uc.TTL)
if err != nil {
return LoginOutput{}, err
}
// トークンと有効期限を返す
return LoginOutput{AccessToken: tok, ExpiresIn: exp}, nilGETリクエストのキャッシュ性に配慮
GET /v1/me は、ログイン済みのユーザー情報を返す際にキャッシュ可能です。認証関連APIでは動的データを扱うため、安全性を確保する目的で、基本的にはキャッシュを無効化するためのヘッダーを設定することが多いみたいです。
アクセストークンやユーザー情報の短時間キャッシュを実装し、コンテンツのやり取りを効率化することができます。
Cache-Control: no-store
Pragma: no-cache設計の階層性
今回の実装は、DDD(ドメイン駆動設計)に基づき、認証機能もいくつかのレイヤーに分離しました。
バックエンド自体、可能な限り疎結合(独立性が高く、他にレイヤーに影響しにくい)設計の原則を守り、特定のクライアントやネットワーク層に依存しない構成にすることで、柔軟性や再利用性を維持できます。
type Deps struct {
Users port.UserRepo // Infrastructure
Hasher port.PasswordHasher // Application Logic
Tokens port.TokenIssuer // Domain Logic
DB *pgxpool.Pool // Infrastructure
ShareTokens port.ShareTokenGenerator // Application Logic
}
func NewRouter(d Deps) http.Handler { ... }未使用(RESTではオプション的なもの)
例えば、クライアントがサーバーからスクリプトを受け取り、実行するケースのことをコード・オンデマンドと呼びます。
このAPI設計では
今回の実装は、RESTアーキテクチャの制約を強く意識した HTTP API であり、
HATEOAS までは踏み込んでいないものの、
「REST風」に留まらない設計判断を行った API であると考えております。
このAPIでは HATEOAS は、採用していません。
モバイルアプリ(iOS)をクライアントとする前提であったので、状態遷移をハイパーメディアで表現するメリットが限定的であり、OpenAPI による契約駆動を優先しました。
HATEOAS:RESTful APIの設計原則の1つで、APIのレスポンスに「次に何ができるか(関連リソースへのリンク)」を含める技術

クリーンアーキテクチャの基本概念は、ソフトウェア設計における依存関係の逆転と責務の分離にあり、ロバート・C・マーチン(通称「アンクルボブ」)によって提唱されました。
マーチン氏は、システムが長期間にわたり変更に強く、メンテナンスが容易であるべきだという考えを強調しています。
ソフトウェア開発の過程で、頻繁に直面する変更要求に柔軟に対応するための手法が求められていたという課題があり、これを解決するための手法としてクリーンアーキテクチャが生まれました。
クリーンアーキテクチャの主要な目標は、ビジネスロジックを外部のインフラから切り離し、独立性を持たせること(疎結合)です。例えばデータベースやUIの変更があっても、ビジネスロジックには影響を与えないように設計されます。
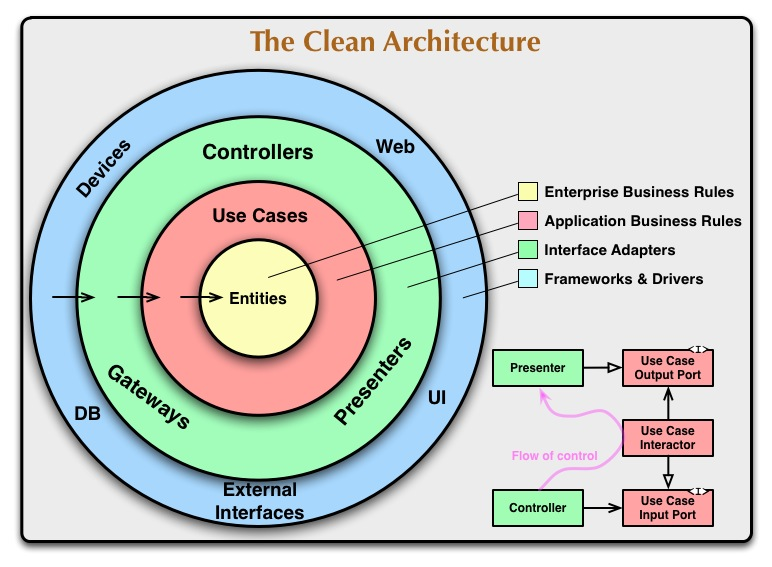
クリーンアーキテクチャは、ビジネスロジックを技術的詳細(DB、UI、フレームワーク)から分離し、保守性・テスト容易性・独立性を高める設計思想です。
中核となる原則は「依存の方向を常に内側(高レベルのビジネスルール=ドメイン知識そのもの)へ向ける」ことであり、外側のレイヤー(低レベルな詳細=UI/データベース周辺)が内側のビジネスロジックに影響を与えない構造のことです。
クリーンアーキテクチャの基本原則の中は、SOLID原則はとても重要な原則となっています。
SOLID原則とは、以下の5つの設計指針を指します。
これらの原則は、クリーンアーキテクチャにおけるモジュール設計の品質を向上させ、保守性の高いシステムを作り上げるための大切な基盤となります。
各エンドポイント(signup, login, me)が明確に一つの役割を果たすように実装しました。
signup: ユーザーの登録login: ログイン処理およびトークン発行me: 認証済みユーザーの情報取得ユーザー認証やトークン発行といった責任を中心にコンポーネントの分離で、コードベース自体も独立した機能ごとに疎結合に構成しました。
ルール
signupUC := authuc.SignupUsecase{Users: d.Users, Hasher: d.Hasher, Tokens: d.Tokens, TTL: 15 * time.Minute}
loginUC := authuc.LoginUsecase{Users: d.Users, Hasher: d.Hasher, Tokens: d.Tokens, TTL: 15 * time.Minute}
getMeUC := meuc.GetMeUsecase{Users: d.Users}
r.Route("/v1", func(r chi.Router) {
r.Post("/auth/signup", ah.SignupHTTP) // signupエンドポイント
r.Post("/auth/login", ah.LoginHTTP) // loginエンドポイント
r.Get("/me", mh.MeHTTP) // meエンドポイント
})今回の実装は、拡張に対してオープンで変更に対してクローズドな構造にしました。
ルール
type PasswordHasher interface {
Hash(plain string) (string, error) // ハッシュ化
Verify(hash, plain string) bool // 検証
}リポジトリやユースケースのようなクラスが抽象化され、さまざまな実装を助けます。
bcryptとargon2(Webアプリのユーザーパスワードを安全に保存するために強力にハッシュ化) などの異なるアルゴリズムの実装を切り替えやすい設計にしました。ルール
type Hasher struct {
Cost int // bcryptのコスト設定
}
func (h Hasher) Hash(plain string) (string, error) {
password, err := bcrypt.GenerateFromPassword([]byte(plain), h.Cost)
return string(password), err
}
func (h Hasher) Verify(hash, plain string) bool {
return bcrypt.CompareHashAndPassword([]byte(hash), []byte(plain)) == nil
}各層が役割ごとに明確に分割し、一部のコードに複数のレイヤーが密結合するリスクを回避する。
PasswordHasherインターフェースは、ハッシュと検証に分離させました。必要最低限のメソッドのみをインターフェースに含めることで、クライアントが意図しない余計なメソッドに依存せずに済むのです。
ルール
type PasswordHasher interface {
Hash(plain string) (string, error)
Verify(hash, plain string) bool
}クリーンアーキテクチャは、ドメイン層に依存しない形でアプリケーションを構築することが強く求められます。
この原則に基づくことで、インフラ層やフレームワークへの依存を薄め、変更に強い設計を持つと言えることができます。
ルール
type Deps struct {
Users port.UserRepo
Hasher port.PasswordHasher
Tokens port.TokenIssuer
DB *pgxpool.Pool
ShareTokens port.ShareTokenGenerator
}
func NewRouter(d Deps) http.Handler {
// DIで依存関係を注入し、高レベルモジュールと低レベルモジュールを分離
loginUC := authuc.LoginUsecase{Users: d.Users, Hasher: d.Hasher, Tokens: d.Tokens, TTL: 15 * time.Minute}
}依存関係は内側から外側に向かってのみ存在可能となっています。
例えば、ドメイン層(内側)は、外部のアプリケーション層およびインフラ層に依存してはならず、その逆にのみ依存が許されます。
ポートとアダプタの使用
port パッケージに抽象化し、これで、アーキテクチャ全体の依存性が逆転。依存関係の注入
ルール
明確な関心事ごとにレイヤリング・分離した実装を意識しました。
ドメイン層(エンティティ、ビジネスルール)、ユースケース層(アプリケーションロジック)、インターフェース層(ユーザーや他のシステムと接続)、インフラ層(データベースや外部API接続)に分離します。
ドメイン層
インターフェース層
internal/adapter/httpフォルダ以下で、http.Handlerなどの外部インターフェースに対する具体的な実装を行いました。ユースケース層
internal/usecaseフォルダ以下に、各特定の業務ロジックを分離しました。LoginUsecaseはログイン処理のみを担当します。インフラ層
infra/db フォルダ以下に実装しました。ルール
ドメイン層(不変条件を保証するVO)
type Email string
func NewEmail(e string) (Email, error) {
e = strings.TrimSpace(strings.ToLower(e))
if e == "" {
return "", errors.New("email is empty")
}
if !emailRegexp.MatchString(e) {
return "", errors.New("email is invalid")
}
return Email(e), nil
}
インターフェース層(ルーティングやエラーハンドリング)
signupUC := authuc.SignupUsecase{Users: d.Users, Hasher: d.Hasher, Tokens: d.Tokens, TTL: 15 * time.Minute}
loginUC := authuc.LoginUsecase{Users: d.Users, Hasher: d.Hasher, Tokens: d.Tokens, TTL: 15 * time.Minute}
getMeUC := meuc.GetMeUsecase{Users: d.Users}
ah := authhttp.AuthHandler{Signup: signupUC, Login: loginUC} // 認証用エンドポイント
mh := mehttp.MeHandler{GetMe: getMeUC} // 現在のユーザー情報取得
r.Route("/v1", func(r chi.Router) {
r.Post("/auth/signup", ah.SignupHTTP) // サインアップ処理
r.Post("/auth/login", ah.LoginHTTP) // ログイン処理
r.Get("/me", mh.MeHTTP) // ユーザー情報取得
})ユースケース層(ログインプロセスの管理)
type LoginUsecase struct {
Users port.UserRepo
Hasher port.PasswordHasher
Tokens port.TokenIssuer
}
func (uc LoginUsecase) Execute(ctx context.Context, in LoginInput) (LoginOutput, error) {
em, err := user.NewEmail(in.Email)
if err != nil { return LoginOutput{}, ErrBadRequest }
rec, err := uc.Users.FindByEmail(ctx, em)
if err != nil || !uc.Hasher.Verify(rec.PasswordHash, in.Password) { return LoginOutput{}, ErrInvalidCredentials }
tok, exp, err := uc.Tokens.IssueAccessToken(rec.ID, uc.TTL)
return LoginOutput{AccessToken: tok, ExpiresIn: exp}, nil
}インフラ層(データベースリポジトリ)
type PostRepository struct {
Pool *pgxpool.Pool
}
func (r *PostRepository) Insert(ctx context.Context, p *dpost.Post) (*dpost.Post, error) {
const q = `
INSERT INTO quote_posts (
user_id, book_id, quote_text, note_text, page, visibility, share_token, created_at
) VALUES (
$1, $2, $3, $4, $5, $6, $7, $8
) RETURNING id, created_at
`
var id string
var createdAt time.Time
err := r.Pool.QueryRow(ctx, q, ...).Scan(&id, &createdAt)
return p, err
}各レイヤーが疎結合であるほど、個別にテストが可能になり、安定した開発を行いやすくなります。
依存注入によるテスト用モックの使用
newMemUserRepo()でメモリ内リポジトリを使用し、外部依存を排除し、bcrypt.HasherのCostもテスト用に軽量化しました。テストケース記述
ルール
users := newMemUserRepo()
hasher := bcrypt.Hasher{Cost: 4}
tokens := jwt.Issuer{Secret: "supersecret_supersecret"}
srv := httptest.NewServer(httpad.NewRouter(httpad.Deps{
Users: users, Hasher: hasher, Tokens: tokens,
}))
signupBody := []byte(`{"email":"test@example.com","password":"password123"}`)
res, err := http.Post(srv.URL+"/v1/auth/signup", "application/json", bytes.NewReader(signupBody))
if res.StatusCode != http.StatusCreated {
t.Fatalf("signup status=%d", res.StatusCode)
}最も内側のレイヤーがドメインモデルであり、その外側にユースケース層、さらにその外側にインターフェース層が配置されます。
ビジネスルール(内側)を守り、外部のインフラとの分離させるようにするために、そのような配置をします。
円形構成に基づくレイヤリング
internal/domain): 業務モデルとビジネスルールinternal/usecase): アプリケーション固有のビジネスロジック(ログイン処理)internal/adapter): 外部へのインターフェースやDBアクセスの実装internal/infra): 基盤依存各レイヤー間は疎結合で設計され、上位レイヤーが下位レイヤーに依存しないようになっています。
ルール
ドメイン層
type User struct {
ID UserID
Email Email
}ユースケース層
func (uc LoginUsecase) Execute(ctx context.Context, in LoginInput) (LoginOutput, error) {
...
}インターフェースアダプタ層
type Deps struct {
Users port.UserRepo
...
}
func NewRouter(d Deps) http.Handler {
...
}フレームワーク&ドライバー層
FROM golang:1.24-alpine AS build
COPY services/backend ./services/backend
RUN go build -o /bin/api ./services/backend/cmd/apiこのAPI設計では
を意識し、ビジネスロジックが外部の詳細(HTTP、DB、フレームワーク)に引きずられない構造を重視して実装しました。

ドメイン駆動設計では「ソフトウェアで問題解決しようとする対象領域」をドメインと呼びます。
ソフトウェア開発の中心に業務知識(ドメイン知識)を置き、スペシャリストとの密な協力を通じて、ドメインモデルを構築することで、ビジネス価値の最大化を目指す手法です。
主な目的は、複雑なドメイン知識を理解し、それをソフトウェアのコードに忠実に反映させることです。
ビジネスニーズ(需要)に最適化されたシステムを構築できます。
重要とした要件
VO (Value Object)は単なるプリミティブ型のラッパーではなく、不変条件を保証する責務を持つべき。
Emailはその妥当性を型によって保証することが重要であり、以下の最低限の要件を決めました。trim(余分なものを取り除く)およびlowercase(小文字化)しておくUsecase層(何をしたいか)でEmail型を扱う際、それが必ず「妥当な値のみ」存在することが保証され、事前に、バグや例外が混入するリスクを大幅に軽減する効果があります。
// Email はメールアドレスを表す値オブジェクト(Value Object)です
// 役割:正規化とバリデーション
package user
import (
"errors"
"regexp"
"strings"
)
// emailの正規表現(最低限なルール)
var emailRegexp = regexp.MustCompile(`^[^\s@]+@[^\s@]+\.[^\s@]+$`)
type Email string
// VOを生成する関数
func NewEmail(e string) (Email, error) {
e = strings.TrimSpace(strings.ToLower(e))
// バリデーション
if e == "" {
return "", errors.New("email is empty")
}
if !emailRegexp.MatchString(e) {
return "", errors.New("email is invalid")
}
return Email(e), nil
}
func (e Email) String() string {
return string(e)
}重要とした要件
認証APIのようにドメインロジックが薄い領域では、エンティティに過剰な振る舞いを詰め込まない
重要なユーザーモデル(利用者)をエンティティに分けて定義することで、責任範囲を明確化しました。挙動(振る舞い)に関する実装はUsecase層(アプリケーションの動作・機能)で処理しました。
package user
type User struct {
ID UserID
Email Email
Role string
}重要とした要件
リポジトリ管理(データの保管場所)を集約単位(オブジェクトの集合体)で分割する。
User, Session)について、専用のリポジトリを作成UserRepoで、ユーザーレポジトリの機能を一元的に管理し、他のエンティティが登場した場合(セッション情報など)、それ専用のリポジトリ分割が容易になるように設計しました。
users := postgres.UserRepo{DB: db}重要とした要件
ドメイン(またはユースケース層)でのエラーは「意味的なエラーメッセージ」を返却する。
ErrEmailExistsのようにドメインで定義ドメインエラー定義
ErrInvalidCredentials で、意味的なエラーがVOやユースケース層で明確に定義しました。var (
ErrInvalidCredentials = errors.New("invalid credentials")
)HTTPレスポンスマッピング
if errors.Is(err, ErrInvalidCredentials) {
http.Error(w, "unauthorized", http.StatusUnauthorized)
return
}このAPI設計では
を通じて、業務ルールや意味をコード上のモデルとして明確に表現することを意識しました。
だと理解しています。
正直、今の段階では少しやりすぎかなと思う部分もありますが、あとから機能を足したり変更したりするときに困らない構成にはなっているとは思っています。
今後の実装を進めながら、設計についても試行錯誤しつつ、理解を深めていけたらいいなと思っています。
https://www.ibm.com/jp-ja/think/topics/rest-apis
https://www.issoh.co.jp/column/details/3406
https://products.sint.co.jp/ober/blog/ddd





